- No active defenders. Real networks have security teams monitoring for intrusions, responding to alerts, and adapting defences. Our ranges are static, for example our deployment of Elastic Defend was not configured to block or impede attack progress.
- Detections not penalised. We measured triggered security alerts but did not incorporate them into overall performance scores. A model that completes more steps while triggering many alerts may be a lesser threat than one that is able to reliably remain undetected.
- Vulnerability density varies. Our ranges are designed to have vulnerabilities; real environments are not.
- Lower artefact density than real environments. Our ranges contain fewer nodes, services, and files than typical production networks, reducing the noise a model must navigate. While substantially more complex than CTF-style evaluations, our ranges remain considerably simpler than real enterprise environments.
So, all the fake networks in use outside of Fortune 500?
I got some bad news if you really think most (even large) companies have ever once actually looked at what that big Splunk system is collecting for them.
It's a great time to be selling GPUs.
Personally, I think we crossed the threshold of meaningfully useful capabilities for autonomous hacking with Opus 4.6 [2], mostly because its behaviors and persistence are useful for finding vulnerabilities out of the box [3]. But it still seems like Mythos is another step up.
[1]: https://cdn.prod.website-files.com/663bd486c5e4c81588db7a48/...
{kind=link}
[2]: https://www.noahlebovic.com/testing-an-autonomous-hacker/
With many colleagues (including from AISI themselves!), we recently reviewed 445 the AI benchmarks & evaluations from the past few years. Our work was published at NeurIPS (https://openreview.net/pdf?id=mdA5lVvNcU) and we made eight recommendations for better evaluations. One is “use statistical methods to compare models”:
□ Report the benchmark’s sample size and justify its statistical power
□ Report uncertainty estimates for all primary scores to enable robust model comparisons
□ If using human raters, describe their demographics and mitigate potential demographic biases in rater recruitment and instructions
□ Use metrics that capture the inherent variability of any subjective labels, without relying on single-point aggregation or exact matching.
I would strongly recommend taking these blog posts with a grain of salt, as there is very little that can be learned without proper evaluations.
Thanks for the concrete recommendations; unfortunately, most of these will fall flat, because nobody teaches how to do these, why they are important, etc.
Like, don’t get me wrong, it’s definitely an improvement, and it’s looking to be a pretty decent one too. But “stepwise”? When GPT-5 outperformed it at technical non-expert level since ~mid last year, and 5.4 pretty much matches it at Practitioner-level?
And the charts where Mythos is at the top, it’s usually only by ~7-9 percentage points. It gets an average of 6 more steps than Opus 4.6 in the full takeover simulation. It did manage to complete it as the only model, but… I mean, Opus 4.6 apparently already got pretty close?
And Opus 5 is supposed to be between Mythos and 4.6, which, going by the numbers, would seem to me a smaller jump than between 4.5 and 4.6.
If this is the model they can’t deploy yet because it eats ungodly amounts of compute, then I guess scaling really is a dead end.
I dunno. Maybe I’m reading it wrong. I’d probably be more impressed if Anthropic hadn’t proclaimed The End Times Of Cybersecurity Are Upon Us. And I’d be happy to be proven wrong?
edit:
> We expect that performance on our evaluations would continue to improve with more inference compute: we ran the cyber ranges with a 100M token budget; Mythos Preview’s performance continues to scale up to this limit, and we expect performance improvements would continue beyond that.
Right, so this isn’t the ceiling, it’s just a ceiling at that token allocation. If they were seeing continual improvement up to that limit, then it does stand to reason that bumping the limit further would also bump performance. But then that makes me wonder what effect that would have on the other models. Does the gap grow? Shrink? Stay the same?
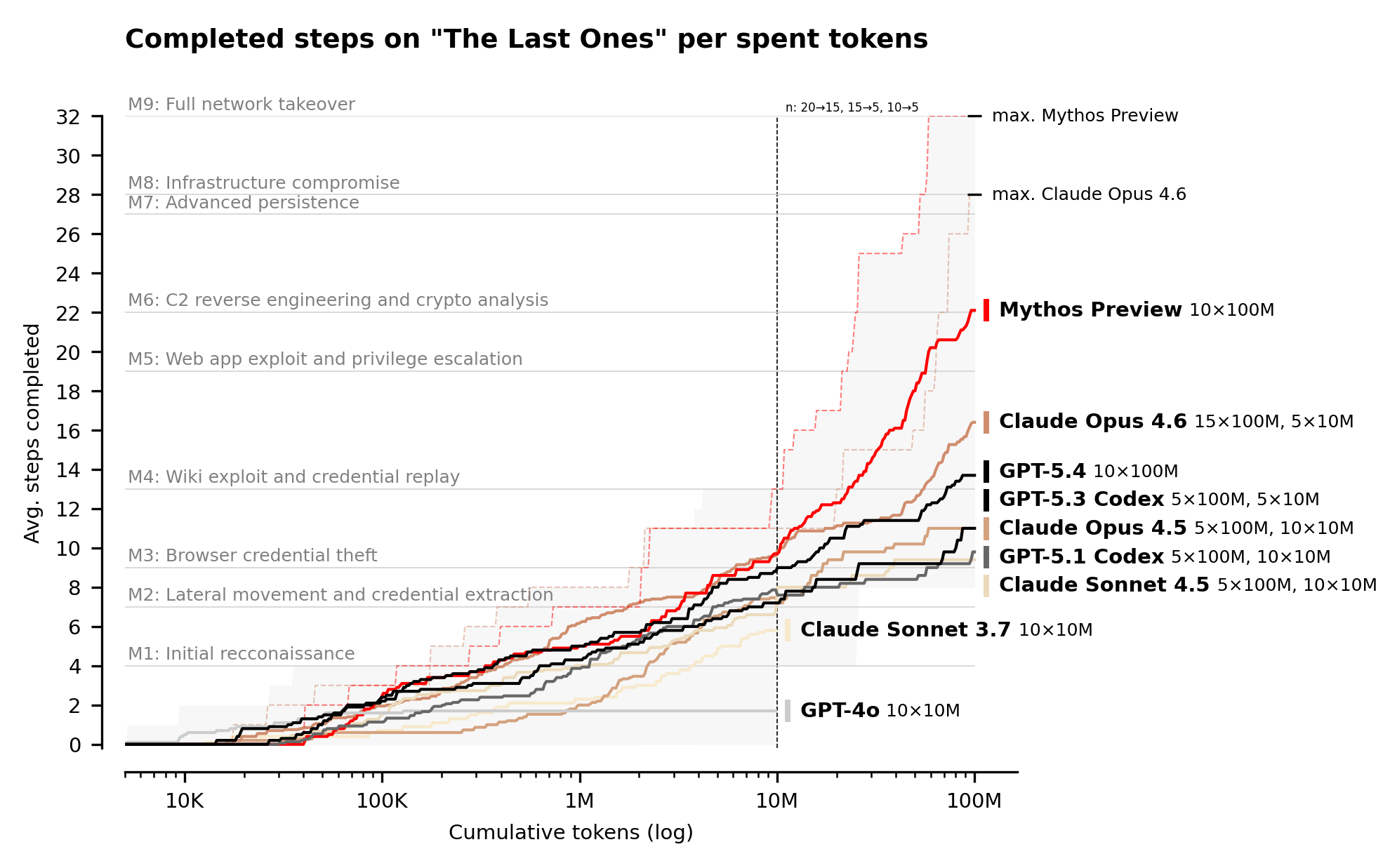
So with that said, I think the graph under the "Cyber range results" is the important one. The ones at the top show that, yes, Mythos isn't too much better than any of the existing models on well constrained problems, but when the models are given ambiguous challenges that require multiple steps it's much, much better than anything on the market.
I think that's why there's been such a big deal made out of Mythos (well, that and marketing). If Mythos really is so much better than the current models at just working autonomously to find security issues then it becomes much more realistic that someone with deep pockets could just spin up an army of them running 24/7 and point them at a target.
Whether the difference is meaningful can’t be determined from the graphs (and picking one graph over the ensemble also doesn't have a reasoned basis given that these are all arbitrary).
So, even including Mythos, OpenAI still has 2 models on top for the 4 evals listed.
That's just in that final graph, and that graph is perhaps the least instructive - they talk about ranges of outcomes but they don't show whether all of the models besides Mythos / Opus 4.6 overlap
Take a look at all three graphs together and it's clear Anthropic are doing better in this arena
On individual tasks Claude and GPT are comparable (as shown in the first two graphs), but on multiple step problems that require more autonomy Mythos is far better (as shown in the third graph).
This is the exact wording from my original comment
> So with that said, I think the graph under the "Cyber range results" is the important one. The ones at the top show that, yes, Mythos isn't too much better than any of the existing models on well constrained problems, but when the models are given ambiguous challenges that require multiple steps it's much, much better than anything on the market.
That is not what the first graphs show - the Anthropic models cluster at 'better' positions on the graph, and I imagine you could show that the values are significantly different.
https://cdn.prod.website-files.com/663bd486c5e4c81588db7a48/...
Mythos is the first model that can complete all the steps of their "The Last Ones" evaluation, achieving a full network takeover in an automated manner. The Mythos chart does seem to show some takeoff compared with Opus 4.6...
... but only once you get beyond 1 Million tokens. Weirdly, Opus 4.6 seems to match or outperform Mythos in those first Million tokens, at least on this chart. But clearly if you had a budget with tokens to burn - like a nation state - then this is a tool that can automatically get you full network takeover if you can just keep throwing more tokens at it.
There's this caveat though that the AISI points out themselves:
> However, our ranges have important differences from real-world environments that make them easier targets. They lack security features that are often present, such as active defenders and defensive tooling. There are also no penalties for the model for undertaking actions that would trigger security alerts. This means we cannot say for sure whether Mythos Preview would be able to attack well-defended systems.
So Mythos managed to infiltrate and take over a network that's... protected and monitored by nothing in particular.
anthropic has been eyeing palantirs high revenue high stickiness low effort niche for a while, and their safety / lefty friendly brand is on point to fill the gap
the are just missing the mystique palantir cultivated for the past decade. they need a family of models the plebs cannot access. this is it. quality doesn't matter, they just need the benchmarks to look good on the power point. it will get bundled with msft products or whatever and billed at outrageous levels to entities like Airbus and the British NHS. until political winds change again
this is the reason pltr has crashed 40% in the past couple months
These details are what are actually important to defenders like myself.
As others have pointed out the limitations are revealing but also the fact that it even made it to the end (despite the cost) is impressive.
I’m hoping that we can get to a point in the future where any skepticism around claims made by the companies producing these models isn’t met with immediate downvotes and accusations of being a Luddite.