Like, don’t get me wrong, it’s definitely an improvement, and it’s looking to be a pretty decent one too. But “stepwise”? When GPT-5 outperformed it at technical non-expert level since ~mid last year, and 5.4 pretty much matches it at Practitioner-level?
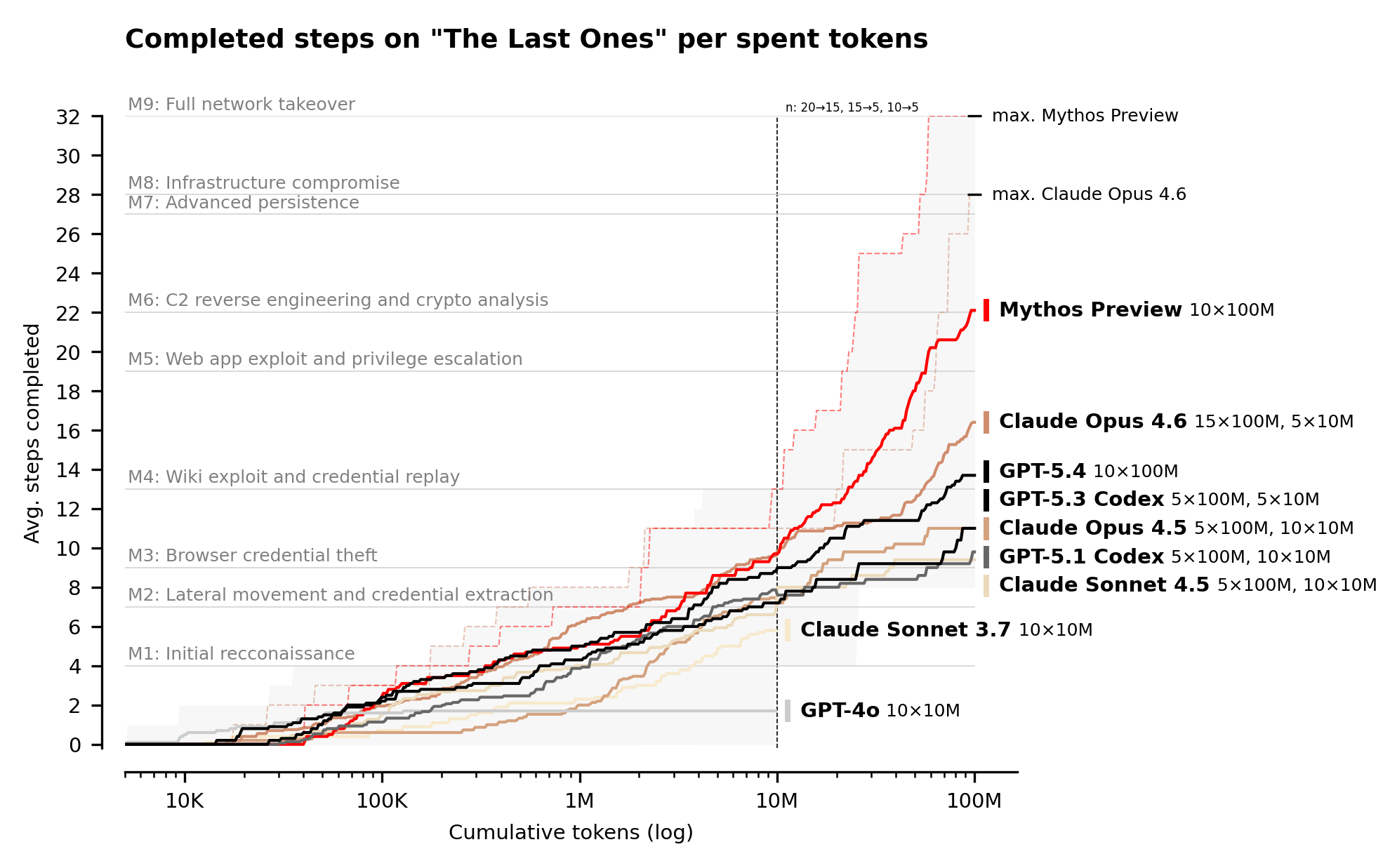
And the charts where Mythos is at the top, it’s usually only by ~7-9 percentage points. It gets an average of 6 more steps than Opus 4.6 in the full takeover simulation. It did manage to complete it as the only model, but… I mean, Opus 4.6 apparently already got pretty close?
And Opus 5 is supposed to be between Mythos and 4.6, which, going by the numbers, would seem to me a smaller jump than between 4.5 and 4.6.
If this is the model they can’t deploy yet because it eats ungodly amounts of compute, then I guess scaling really is a dead end.
I dunno. Maybe I’m reading it wrong. I’d probably be more impressed if Anthropic hadn’t proclaimed The End Times Of Cybersecurity Are Upon Us. And I’d be happy to be proven wrong?
edit:
> We expect that performance on our evaluations would continue to improve with more inference compute: we ran the cyber ranges with a 100M token budget; Mythos Preview’s performance continues to scale up to this limit, and we expect performance improvements would continue beyond that.
Right, so this isn’t the ceiling, it’s just a ceiling at that token allocation. If they were seeing continual improvement up to that limit, then it does stand to reason that bumping the limit further would also bump performance. But then that makes me wonder what effect that would have on the other models. Does the gap grow? Shrink? Stay the same?
So with that said, I think the graph under the "Cyber range results" is the important one. The ones at the top show that, yes, Mythos isn't too much better than any of the existing models on well constrained problems, but when the models are given ambiguous challenges that require multiple steps it's much, much better than anything on the market.
I think that's why there's been such a big deal made out of Mythos (well, that and marketing). If Mythos really is so much better than the current models at just working autonomously to find security issues then it becomes much more realistic that someone with deep pockets could just spin up an army of them running 24/7 and point them at a target.
Whether the difference is meaningful can’t be determined from the graphs (and picking one graph over the ensemble also doesn't have a reasoned basis given that these are all arbitrary).
So, even including Mythos, OpenAI still has 2 models on top for the 4 evals listed.
That's just in that final graph, and that graph is perhaps the least instructive - they talk about ranges of outcomes but they don't show whether all of the models besides Mythos / Opus 4.6 overlap
Take a look at all three graphs together and it's clear Anthropic are doing better in this arena
On individual tasks Claude and GPT are comparable (as shown in the first two graphs), but on multiple step problems that require more autonomy Mythos is far better (as shown in the third graph).
This is the exact wording from my original comment
> So with that said, I think the graph under the "Cyber range results" is the important one. The ones at the top show that, yes, Mythos isn't too much better than any of the existing models on well constrained problems, but when the models are given ambiguous challenges that require multiple steps it's much, much better than anything on the market.
That is not what the first graphs show - the Anthropic models cluster at 'better' positions on the graph, and I imagine you could show that the values are significantly different.
https://cdn.prod.website-files.com/663bd486c5e4c81588db7a48/...
{kind=link}
Mythos is the first model that can complete all the steps of their "The Last Ones" evaluation, achieving a full network takeover in an automated manner. The Mythos chart does seem to show some takeoff compared with Opus 4.6...
... but only once you get beyond 1 Million tokens. Weirdly, Opus 4.6 seems to match or outperform Mythos in those first Million tokens, at least on this chart. But clearly if you had a budget with tokens to burn - like a nation state - then this is a tool that can automatically get you full network takeover if you can just keep throwing more tokens at it.
There's this caveat though that the AISI points out themselves:
> However, our ranges have important differences from real-world environments that make them easier targets. They lack security features that are often present, such as active defenders and defensive tooling. There are also no penalties for the model for undertaking actions that would trigger security alerts. This means we cannot say for sure whether Mythos Preview would be able to attack well-defended systems.
So Mythos managed to infiltrate and take over a network that's... protected and monitored by nothing in particular.
anthropic has been eyeing palantirs high revenue high stickiness low effort niche for a while, and their safety / lefty friendly brand is on point to fill the gap
the are just missing the mystique palantir cultivated for the past decade. they need a family of models the plebs cannot access. this is it. quality doesn't matter, they just need the benchmarks to look good on the power point. it will get bundled with msft products or whatever and billed at outrageous levels to entities like Airbus and the British NHS. until political winds change again
this is the reason pltr has crashed 40% in the past couple months
I suspect Anthropic gave them early access hoping for a marketing win and ended up with their arse being served to them on a plate.
All rather predictable really. As you say "more compute needed" as the default answer from the AI companies is completely unsustainable.
As for the value of Anthropic blog posts, well...
The actual result is TLO, and "only 6 more steps" in OP misreads how sequential attack chains work. These aren't independent puzzles. Each step gates the next. Averaging 22 vs 16 means Mythos is consistently punching through bottlenecks that completely stop Opus 4.6. More importantly: Mythos completed the full chain 3/10 times. Opus 4.6 completed it 0/10 times. That's not a narrow margin. In any security-relevant framing, "achieves full network takeover" vs "does not achieve full network takeover" is a binary threshold, and exactly one model crossed it. A year ago the best models struggled with beginner CTFs. Now one autonomously replicates what AISI estimates takes human professionals 20 hours. Calling that unimpressive because the margin over second place is single digits is measuring the wrong gap.
re: compute, "requires lots of compute" and "scaling is a dead end" are near-opposite claims. If performance is still climbing at 100M tokens with no visible plateau, that's evidence scaling works. Whether it's cheap today is a different question, and not one that ages well. Compute costs fall reliably, so what matters is the capability at a given price point in 18 months, not today.
The underlying point still stands, namely that "more compute" as the default answer is not sustainable.
Why ?
Because even if we accept the unlikely dream that GPU prices will magically take a nose-dive, you still need somewhere to put all those servers stuffed with GPUs.
That means datacentres.
And "more datacentres" is absolutely not sustainable.
The cooling needs, the power needs, the land needs..... none of it is remotely sustainable.